Project Description
Given the availability of large-scale source-code repositories, there have been a large number of applications for clone detection. Unfortunately, despite a decade of active research, there is a marked lack in clone detectors that scale to large software repositories. In particular for detecting near-miss clones where significant editing activities may take place in the cloned code.We present SourcererCC, a token-based clone detector that targets the first three clone types, and exploits an index to achieve scalability to large inter-project repositories using a standard workstation. SourcererCC uses an optimized inverted-index to quickly query the potential clones of a given code block. Filtering heuristics based on token ordering are used to significantly reduce the size of the index, the number of code-block comparisons needed to detect the clones, as well as the number of required token-comparisons needed to judge a potential clone.
We evaluate the scalability, execution time, recall and precision of SourcererCC, and compare it to four publicly available and state-of-the-art tools. To measure recall, we use two recent benchmarks, (1) an exhaustive benchmark of real clones, BigCloneBench, and (2) a Mutation/Injection-based framework of thousands of fine-grained artificial clones. We find SourcererCC has both high recall and precision, and is able to scale to a large inter-project repository (250MLOC) using a standard workstation.
Tool Download and Usage
In order to run the tool please follow the steps below:A. Generating the input file of the project for which you want to detect clones
- Click here to download input generator for the code clone detector (ast.zip).
- Unzip ast.zip and import the project ast in your eclipse workspace.
- Run it as an "Eclipse Application". This should open another eclipse instance where you will import the projects for which you want to generate the input file.
- After importing the project in the workspace of the new eclipse instance, click on the "Sample Menu" in the top menu bar and then click on the "Sample command" to run. This should generate the output (desired input file) in the path specified by variable "outputdirPath".
- Please note that you will have to change the location of output directory on line 61 of SampleHandler.java.
this.outputdirPath = "/Users/vaibhavsaini/Documents/codetime/repo/ast/output/";to your desired output directory. - The generated input file name will be of the format: <ProjectName>-clone-INPUT.txt. For example, if your project name is jython, then the generated input file name should be jython-clone-INPUT.txt
B. Running the clone detection tool on the generated input file
- Click here to download the CloneDetector (tool.zip).
- Unzip tool.zip and navigate to tool/ using terminal
- Copy the input file generated above (<ProjectName>-clone-INPUT.txt) into input/dataset directory.
- Open cd.sh, and assign <ProjectName> as value to the variable
arrayname(line #5). For example, If your generated input file is jython-clone-INPUT.txt, line #5 should bearrayname=(jython) - Execute the command
./cd.sh
C. Generated output
- The generated output will be in the ./output folder.
- Files with extension .txt will have the computed clones and the files with .csv extension will have the time taken to detect clones
The source code of SourcererCC can be found here on github.
E. SourcererCC-I
SourcererCC-I is an interactive version of the tool integrated with Eclipse IDE to help developers instantly find clones during software development and maintenance.
A short video of Sourcerer-I in action can be found here and link to install the Eclipse plug-in is available here.
Precision data as reported in the paper
We randomly selected 390 of clone pairs detected by SourcererCC for manual inspection. This is a statistically significant sample with a 95% confidence level and a +/- 5% confidence interval. We split the validation efforts across three clone experts. This prevents any one judge's personal subjectivity from influencing the entire measurement. The judges found 355 to be true positives, and 35 to be false positives, for a precision of 91%.| Reviewer | True Positives | False Positives |
|---|---|---|
| Judge 1 | TP-1 | FP-1 |
| Judge 2 | TP-2 | FP-2 |
| Judge 3 | TP-3 | FP-3 |
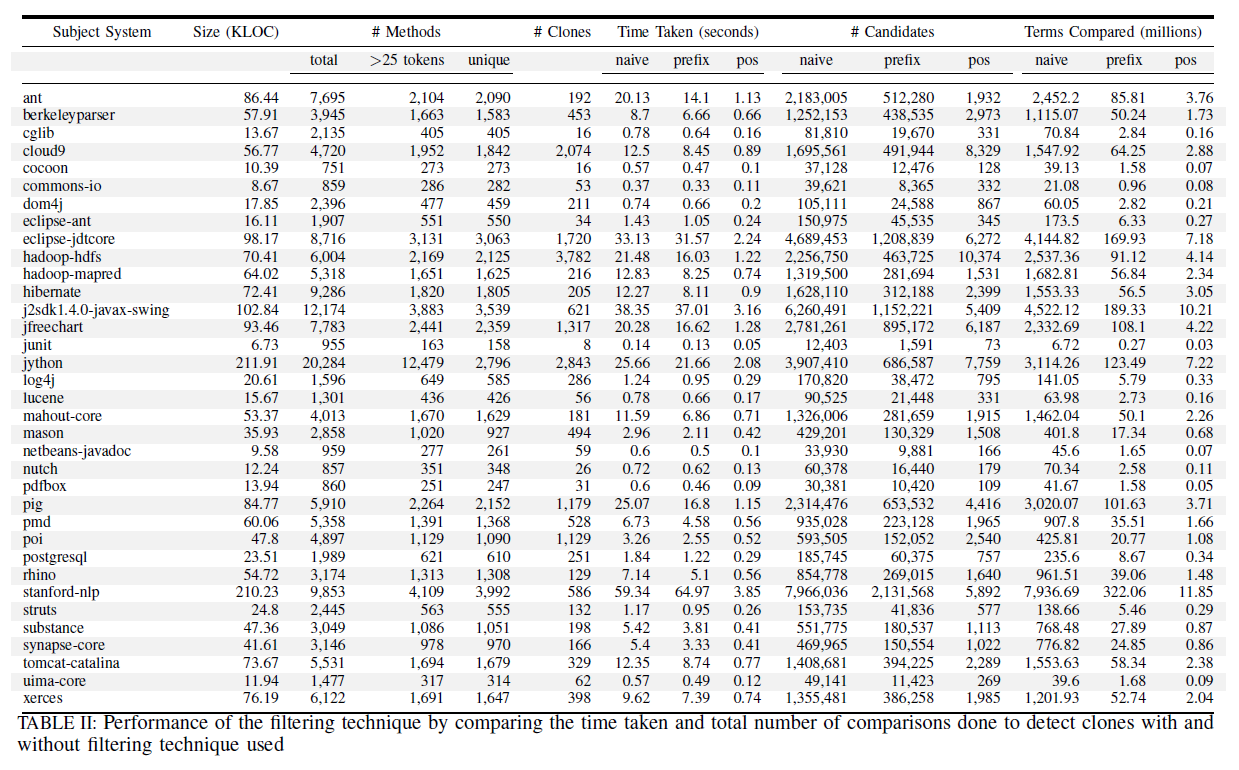
Effectiveness of Filtering Heuristics (Figure 1 in paper)
The effectiveness of the filtering heuristics to eliminate candidate comparisons is demonstrated on 35 open source Apache Java projects. These projects are of varied size and span across various domains including search and database systems, server systems, distributed systems, machine learning and natural language processing libraries, network systems, etc. Most of these subject systems are highly popular in their respective domain. Such subject systems exhibiting variety in size and domain help counter a potential bias of our study towards any specific kind of software system The details of the projects including project name, size and the number of methods is reported in Table II below. Column 3 ( # Methods) shows total number of methods (total), number of methods after removing methods with size < 25 tokens (>25 tokens), and methods that are not exact duplicates (unique). Column 5 (Time Taken), Column 6 (# Candidates) and Column 7 (Terms Compared) show time taken to detect clones, number of candidates compared and total number of tokens compared for:(i) Naive - No filtering heuristics;
(ii) Prefix - Sub-block filtering heuristic; and
(iii) Pos - Both Sub-block and Token Position filtering heuristics together
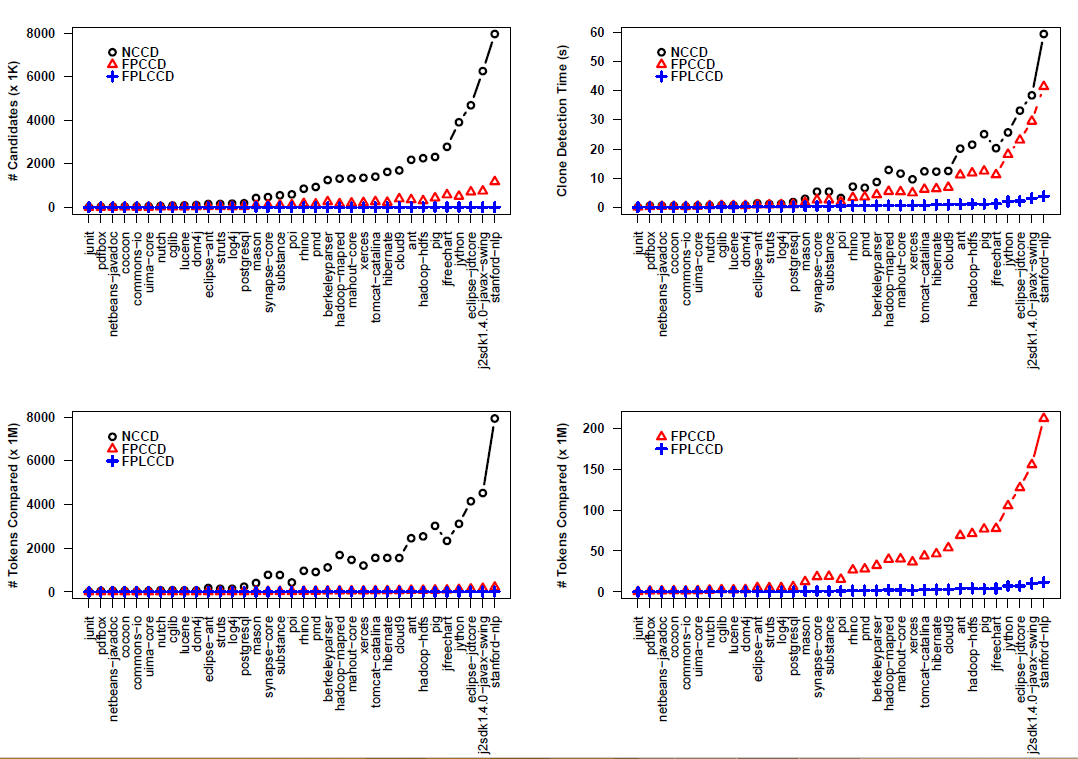
The tabulated data is also charted below. The horizontal axis shows the 35 subject systems sorted by the number of methods they contain (smallest on the left) . The vertical axis shows the performance metric value. The black circles, the red triangles, and the green plus marks show the performance metric values of when no filtering is applied, only sub-block filtering is applied, and sub-block and token position filtering applied respectively.